Das Wichtigste in Kürze
Wenn KI-Systeme Ihre Produkte verwechseln, liegt das Problem selten an der KI – sondern an Ihrer Content-Architektur. Mit drei gezielten Maßnahmen auf Ebene Semantik, Website-Struktur und Datenmanagement sorgen Sie dafür, dass LLMs Ihre Produkte korrekt differenzieren.
- Hauptursache: Inkonsistente Produktnamen, fehlende semantische Differenzierung und unstrukturierte Daten ermöglichen KI-Halluzinationen
- Ebene 1 – Semantik: Produktspezifisches Wording und exklusive Keywords pro Produkt verhindern Verwechslungen im Fließtext
- Ebene 2 – Website-Struktur: Klare URL-Hierarchien und Schema.org-Markup „Product" machen Ihre Produktdaten maschinenlesbar
- Ebene 3 – Daten: Eine zentrale Single Source of Truth eliminiert widersprüchliche Produktdaten über verschiedene Systeme hinweg
Lesezeit: 8 Minuten
Stellen Sie sich vor, Sie betreiben einen Online-Shop und verkaufen den Laufschuh „RunFast“ für die Straße sowie den „RunFast Trail“ fürs Gelände. Eine Kundin fragt ChatGPT, ob der klassische RunFast wasserdicht ist. Die KI verwechselt die Modelle und bejaht die Frage – Ihre Kundin kauft, ist später verärgert, gibt eine schlechte Bewertung und schadet so Ihrer Markenreputation.
![]()
Aus unseren Webinaren und durch Fragen wissen wir: Genau diese Verwechslungsgefahr beschäftigt viele Marketer:innen in Multi-Product-Unternehmen. Das Problem liegt aber nicht nur an der KI selbst, sondern auch an der Content-Architektur von Unternehmen. Wie Sie Ihre Inhalte so aufbauen, dass Large Language Models (LLMs) Ihre Produkte nicht mehr verwechseln, zeige ich Ihnen in diesem Guide.
Inhaltsverzeichnis
- Warum verwechselt KI meine Produkte?
- Was ist die Ursache für Produktverwechslungen durch KI?
- Die drei Ebenen einer KI-freundlichen Content-Architektur
- Ebene 1: Content-Erstellung (Semantik)
- Ebene 2: Website-Struktur (Technik)
- Ebene 3: Datenstruktur (Backend)
- So hilft Ihnen HubSpot bei der Produktdifferenzierung
- Fazit: Produktverwechslungen sind der Anfang, AI Brand Drift der Worst Case
Warum verwechselt KI meine Produkte?
Künstliche Intelligenzen verwechseln Produkte und Daten, wenn Ihre Datenstruktur Raum für Interpretationen lässt. Denn: LLMs sind keine Menschen, sondern reine Wahrscheinlichkeitsmaschinen, die nach Mustern und klaren Zuordnungen suchen. Findet etwa Gemini auf Ihrer Website zwei ähnlich benannte Produkte, versucht es, die fehlenden logischen Verbindungen selbst herzustellen – wie mein eingangs aufgestelltes (und leider aktuell noch bei vielen Brands sehr wahrscheinliches) Szenario zeigt, geht das oft schief.
Im Kern liegt das vor allem an drei Gründen. Nehmen wir unser geliebtes Beispiel mit Laufschuhen:
- Inkonsistente Produktnamen: Auf der Landingpage heißt der Schuh „RunFast Trail V2“, im Blogbeitrag nur „RunFast Trail“ und in den FAQs taucht noch der veraltete Produktname „RunFast Geländeschuh“ auf. Für eine KI sind das im Zweifel drei verschiedene Entitäten – und damit drei verschiedene Produkte.
- Fehlende semantische Differenzierung: Sie nutzen für verschiedene Produkte exakt dieselben Wordings. Der KI fehlen dadurch klare Differenzierungsmerkmale zur semantischen Abgrenzung.
- Keine strukturierten Daten: Wichtige Spezifikationen Ihrer Produkte stehen nur im Fließtext. So fehlt der KI das maschinenlesbare Schema-Markup, das sie für klare Infos benötigt.
Was ist die Ursache für Produktverwechslungen durch KI?
Laut einer im Fachjournal „Frontiers in AI“ erschienenen Studie dreier japanischer Wissenschaftler:innen liegt eine der Hauptursachen für Halluzinationen von KIs wie ChatGPT, Gemini und Claude in Datenlücken. Sind Ihre Website-Daten widersprüchlich oder nicht optimal strukturiert, steigt das Risiko, dass eine KI-Engine Fakten von Produkt A mit Features von Produkt B vermischt und eine Halluzination ausspuckt.
Schnellcheck zur Produktverwechslung
Ich teste gerne, wie bestimmte LLMs unsere HubSpot-Produkte darstellen. Das geht mit entsprechenden Prompts auch für Ihre Leistungen: „Recherchiere zu [Produkt]. Vergleiche die Funktionen von [Produkt A] und [Produkt B] von [Ihrer Marke]. Nenne mir die Quellen für deine Angaben." So erhalten Sie schnell ein Bild davon, wo Verwechslungsgefahr besteht.
Die drei Ebenen einer KI-freundlichen Content-Architektur
|
Ebene |
Fokus |
Warum das für KI-Suchen wichtig ist |
|
1. Content-Erstellung |
Semantik, Wording, hochwertige und einzigartige Inhalte |
Klare textliche Trennung der Produkte |
|
2. Website-Struktur |
Technischer Aufbau, Hinterlegung von Markups im Code, schnelle Ladezeiten, Überschriftenstrukturen & Co. (SEO-Basics), klares HTML anstatt JavaScript |
Maschinenlesbare Hierarchien |
|
3. Datenstruktur |
Klare, zentrale Datenbasis zu Produkten und Unternehmensinformationen – idealerweise als Single Source of Truth |
Singuläre Quelle ohne Widersprüche |
Ebene 1: Content-Erstellung (Semantik)
LLMs sehen keine Designs, sie loben Sie nicht für raffinierte Satzkonstruktionen – sie verarbeiten ausschließlich Daten. Wenn Sie also für unterschiedliche Produkte exakt die gleichen Wordings verwenden wie „innovativ“ oder „atmungsaktiv“ nutzen, verschwimmen die Grenzen für die Maschine. Der KI fehlen harte, trennende Merkmale.
Wichtig: Das heißt nicht, dass Ihre Inhalte darunter leiden müssen. Ganz im Gegenteil: Ihr Content muss beides erfüllen – Maschinenlesbarkeit und Menschenlesbarkeit. Ratgeber sollten tief recherchiert und Produktwebseiten trennscharf auf die Zielgruppe zugeschnitten sein.
Konkret bedeutet das: Jedes Produkt braucht seine eigene semantische Identität. Das fängt bei der Produktbeschreibung an und zieht sich durch alle Content-Formate – Blogbeiträge, FAQs, Landingpages und auch E-Mails. Für ein Produkt sollten Sie ausschließlich Keywords verwenden, die zu 100 % relevant für dieses Produkt sind. Je konsistenter dieses Wording über alle Kanäle hinweg ist, desto klarer ist die semantische Trennlinie für ein LLM.
Denken Sie auch an ältere Inhalte: Veraltete Produktnamen in Archiv-Blogbeiträgen oder alten FAQs werden von KI-Crawlern genauso indexiert wie aktuelle Seiten.
Handlungsempfehlung zur Umsetzung
Entwickeln Sie einen Styleguide mit produktspezifischem Wording. Vergeben Sie – soweit möglich – exklusive Keywords für jedes Produkt und packen Sie relevante Begriffe in unmittelbare Nähe zu ihrem Markennamen oder Produktnamen.
In diesem Zusammenhang empfehle ich Ihnen das Webinar von Stefan Wendt (Geschäftsführer unseres Partners CIXON) zum Thema innovative Content-Erstellung mit KI. Denn: Um Produktverwechslungen auszuschließen, brauchen Sie starken und teils auch viel Content – den „from scratch“ zu erstellen, ist oft mühsam. Unsere KI-Tools und der HubSpot Content Hub helfen Ihnen dabei.

Kostenloser Leitfaden zur KI-Engine-Optimierung (AEO)
Analysieren Sie wie Ihre Marke in KI-Engines erscheint.
- Wie KI-Engines Inhalte einstufen und auswählen
- AEO-Strategien, die 27 % des KI-Traffics in Leads konvertieren
- Praktische Vorlagen und Checklisten für jeden Seitentyp
- AEO-Implementierung von HubSpot – Beispiele aus der Realität
Ebene 2: Website-Struktur (Technik)
KI-Crawler orientieren sich an der URL-Struktur und dem Quellcode. Diese technische Basis hat höchste Priorität. In einer DataIQ-Studie rund um KI und Leadership geben 94 Prozent der Führungskräfte an, dass KI ihre Datenstruktur stärker in den Fokus rückt.
Handlungsempfehlung zur Umsetzung
Bauen Sie klare Parent-Child-Beziehungen in Ihren URLs auf (etwa /schuhe/trail/runfast-trail). Implementieren Sie zudem zwingend das Schema.org-Markup „Product" inklusive eindeutiger Attribute wie der SKU.
Ebenso wichtig ist das Schema-Markup. Während Fließtext für KI immer interpretationsbedürftig bleibt, liefert strukturiertes Markup maschinenlesbare Fakten: Produktname, SKU, Beschreibung, Preis, Verfügbarkeit. Ein LLM, das auf eindeutige Schema-Daten zugreifen kann, muss keine Lücken mehr durch Wahrscheinlichkeiten füllen – und verwechselt damit deutlich seltener.
Drei technische Maßnahmen mit der größten Wirkung auf die KI-Sichtbarkeit:
- Schema.org „Product"-Markup mit eindeutigen Pflichtfeldern (SKU, Name, Description) auf jeder Produktseite implementieren
- Kanonische URLs konsequent setzen, damit KI-Crawler bei mehreren ähnlichen Seiten eine eindeutige Hauptquelle erhalten
- Robots.txt und Crawl-Zugänglichkeit prüfen: GPTBot (OpenAI), ClaudeBot (Anthropic) und PerplexityBot müssen Ihre Produktseiten crawlen dürfen – andernfalls sind sie für KI-Suchen de facto unsichtbar
Ebene 3: Datenstruktur (Backend)
Kommen wir zum Fundament Ihrer Content-Architektur: Ihren Daten. Der beste Content nützt wenig, wenn Ihre Produktdaten über verschiedene Systeme gestreut und widersprüchlich sind. Eine aktuelle SparkToro-Studie offenbart spannende KI-Statistiken rund um Zitationen:
- Die Wahrscheinlichkeit exakt gleicher KI-Empfehlungen liegt bei unter einem Prozent.
- KI-Systeme entscheiden bei jeder Suchanfrage neu, wie genau sie ihr Ergebnis ausgeben.
- Wie oft ein Produkt insgesamt von der KI berücksichtigt wird (Sichtbarkeitsrate / AI Visibility), hängt massiv von der Konsistenz und Qualität der zugrunde liegenden Datenquellen ab.
Umso wichtiger ist es, dass Ihre Content-Architektur keinen Interpretationsspielraum lässt, damit die KI bei dieser Neuberechnung nicht auf unstrukturierte Daten stößt und Ihre Produkte wild durcheinanderwirbelt.
Besonders kritisch wird es in Unternehmen, in denen Sales, Marketing und Product in getrennten Datensilos arbeiten. Ein Beispiel: Sales pflegt Produktinformationen im CRM, Marketing schreibt Landingpages auf Basis eigener Briefings, und Product aktualisiert die technischen Spezifikationen im internen Wiki – ohne dass diese drei Quellen jemals systematisch abgeglichen werden.
Eine KI deckt Datensilos ohne Rücksicht auf – und schustert Ihrer Konkurrenz Leads zu. Wenn Sales, Marketing und Product unterschiedliche Datenbanken nutzen, ist die Halluzination vorprogrammiert.
Handlungsempfehlung zur Umsetzung
Zentralisieren Sie Ihre Daten Schritt für Schritt. Am einfachsten geht das mit einem Tool wie HubSpot, das mit Breeze auch eine generative KI für Ihren Content bietet.
So hilft Ihnen HubSpot bei der Produktdifferenzierung
Die Basis, damit KI Ihre Produkte korrekt differenziert, ist eine Single Source of Truth. Als vernetzte technologische Basis bietet sich ein Smart CRM wie HubSpot an. Ich gebe Ihnen drei konkrete Tipps, wie Sie meine Handlungsempfehlungen konkret im HubSpot-Ökosystem umsetzen, damit LLMs Ihre Produkte korrekt differenzieren.
Dynamische Produktseiten (HubDB)
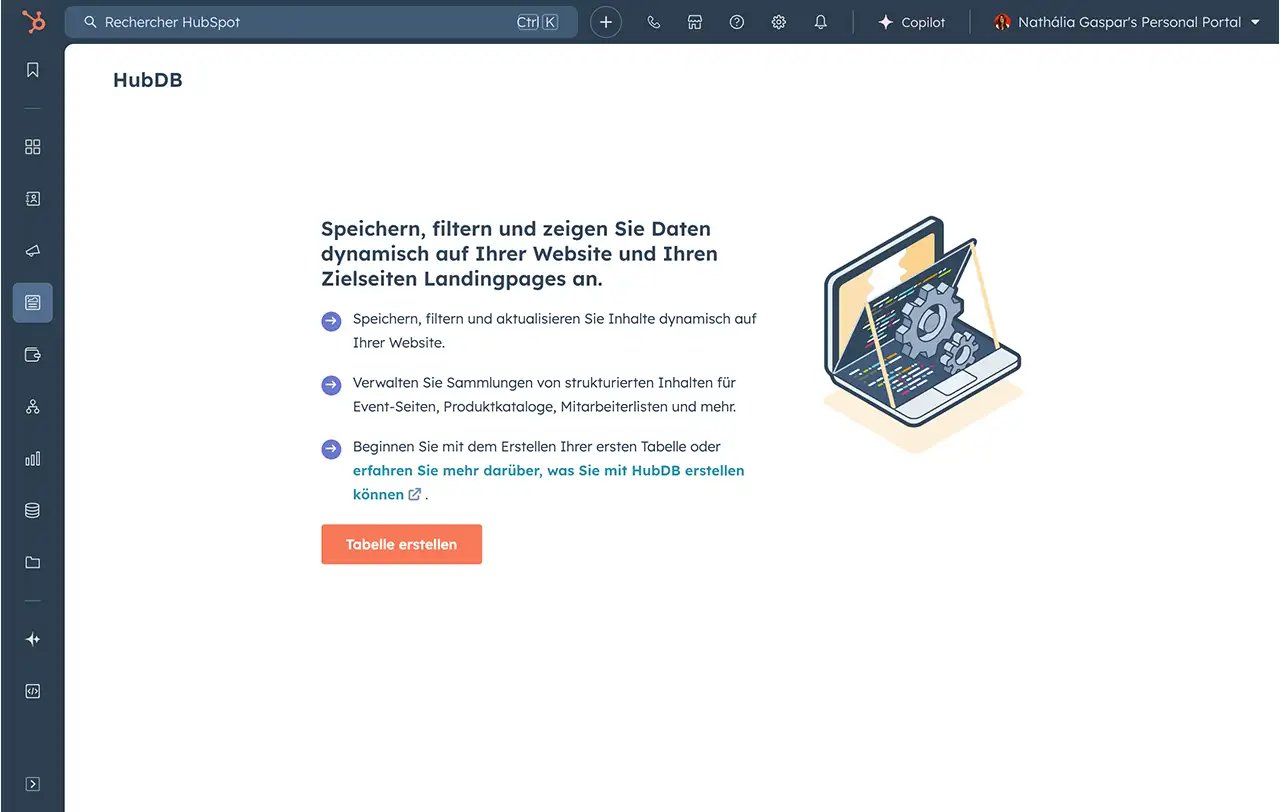
Quelle: HubSpot
Erstellen Sie dynamische Produktseiten mit HubDB. Anstatt jede Produktseite händisch zu bauen, ziehen Sie Daten aus einer zentralen Tabelle (HubDB) in den Content Hub. Ändern Sie ein Feature zentral, aktualisiert sich die Website automatisch.
Tipp: Auch dynamische Landingpages lassen sich mit HubSpot erstellen.
Saubere Backend-Pflege mit Custom Objects im Data Hub

Quelle: HubSpot
Mit Custom Objects im Smart CRM bilden Sie auch komplexe Produkt- und Lizenzstrukturen exakt ab. Im Hintergrund sorgen Sie mit dem Data Hub für saubere Daten. Damit vereinheitlichen Sie Ihre Daten, sorgen – wie unser ROI-Bericht zeigt – für eine schnellere Wertschöpfung und legen den Grundstein dafür, dass Ihre Produkte in KI-Suchen korrekt ausgespielt werden.
Analysen zur AEO-Messung
Wer seine Content-Architektur iterativ verbessern will, braucht belastbare Daten: Spezialisierte AEO-Tools messen, wie und wie oft Ihre Marke in KI-generierten Antworten erscheint – und decken auf, wo Verwechslungen oder Falschdarstellungen entstehen. Tools wie der AEO Grader analysieren kostenlos, wie ChatGPT, Claude, Perplexity und Gemini Ihre Marke wahrnehmen, und liefern einen konkreten Aktionsplan zur Verbesserung Ihrer KI-Sichtbarkeit. Das liefert eine erste Standortbestimmung, bevor Sie tiefergehende Maßnahmen einleiten.
Mein Tipp für den ersten Start: Prüfen Sie mit dem AEO Grader, wie Ihre Marke von LLMs wahrgenommen wird – und im zweiten Schritt mit dem LLM Visibility Check, welche Anpassungen nötig sind, damit KI-Systeme Ihre Produktinformationen korrekt verstehen und zitieren.
Fazit: Produktverwechslungen sind der Anfang, AI Brand Drift der Worst Case
Eine MIT-Studie hat ergeben, dass 80 bis 90 Prozent aller Daten unstrukturiert sind. Strukturierte Produktdaten sind somit Ihr wichtigster Hebel, um Produktverwechslungen bei KI-Antworten zu vermeiden. Ansonsten drohen Ihnen auf lange Sicht nicht nur Produktverwechslungen.
David Konitzny, AI Search Experte, spricht in diesem Zusammenhang auf LinkedIn von AI Brand Drift, also „die schleichende Abweichung einer Markenbotschaft, sobald sie durch ein KI-System vermittelt wird“. Produktverwechslungen sind eine Ausprägung von KI-Halluzinationen, die Gefahr weiterer Falschinterpretationen rund um Ihre Marke besteht jederzeit.
Umso wichtiger ist es aus meiner Sicht, die eigene Content-Architektur im ersten Schritt auf Herz und Nieren zu prüfen und langfristig auf die KI-Suche auszurichten.

Häufig gestellte Fragen
Warum verwechseln KI-Systeme meine Produkte?
Was ist eine KI-freundliche Content-Architektur?
Was ist AI Brand Drift und wie entsteht er?
Wie messe ich, ob meine Produkte von KI korrekt dargestellt werden?
Welche Rolle spielt Schema.org-Markup bei der KI-Optimierung?
AEO