Wenn es um die Platzierung in den Suchergebnisseiten von Google geht, gibt es bestimmte Methoden und Vorgehensweisen, die der Algorithmus besonders hart bestraft. Eine davon ist Duplicate Content. Dabei handelt es sich um Inhalte, die nahezu identisch auf verschiedenen Seiten erscheinen. Das Problem daran: gleiche Inhalte, die über mehrere URLs erreichbar sind, haben einen negativen Einfluss auf das Suchmaschinen-Ranking.

Wie Sie Duplicate Content ausfindig machen und beseitigen können, haben wir für Sie hier zusammengefasst.
![]()
Was ist Duplicate Content?
Der Begriff Duplicate Content (DC) bezeichnet synonyme Inhalte, die über verschiedene URLs erreichbar sind. Unterschieden wird zwischen internem DC (auf der eigenen Website) und externem DC (auf unterschiedlichen Domains). Aufgrund des damit verbundenen negativen Nutzererlebnisses straft Google das Vorkommen von DC – wenn dieser nicht explizit ausgewiesen wurde – mit einer verringerten SEO-Performance ab.
Was genau ist Duplicate Content?
Werden größere Content-Blöcke einer Webseite oder die komplette (Einzel-)Seite kopiert und an anderer Stelle veröffentlicht, entsteht Duplicate Content. Derselbe Content liegt also doppelt an mehreren Orten vor, sodass Suchmaschinen nicht zuverlässig entscheiden können, welche Version des Inhalts die höchste Relevanz hat und im Suchmaschinen-Ranking oben erscheinen soll. Deshalb sollte duplizierter Content von Webmastern ernst genommen werden.
Suchmaschinen wollen die Nutzerschaft allerdings mit treffgenauen Suchergebnissen beliefern und dadurch eine passgenaue „User Experience“ über- und vermitteln. Ergebnisse mit identischen Inhalten werden bei Suchanfragen deutlich weniger angezeigt. Stattdessen ist die Suchmaschine gezwungen eine Version auszuwählen, die am passendsten erscheint.
Ab wann spricht man von Duplicate Content?
Selbstverständlich gilt nicht jeder gleiche Satz sofort als DC. Wenn Sie beispielsweise Zitate verwenden und diese semantisch im Quelltext als solche angeben, wertet Google dies nicht als identisch. Auch Inhalt in mehreren Sprachversionen gilt nicht als Duplicate Content, zumindest wenn dabei keine unterschiedlichen Domains ins Spiel kommen.
Wenn Sie allerdings größere Teile von einer Seite kopieren und auf einer anderen Seite einfügen, haben Sie Duplicate Content geschaffen. Es reicht also nicht aus, jeden zweiten Satz ein bisschen umzuformulieren, da Google „derart unfaire Verhaltensweisen“ sofort bemerkt.
Häufige Ursachen für Duplicate-Content
Im Folgenden zeigen wir, wie doppelter Content auf Webseiten entstehen kann.
Interner Duplicate Content
Von internem Duplicate Content spricht man, wenn sich auf einer Domain, die über verschiedene URLs erreichbar ist, der gleiche Content finden lässt. Meist kommt interner DC unbewusst zustande, beispielsweise durch Beiträge und Seiten, die mehreren Kategorien zugewiesen werden können. So bilden sich verschiedene Linkstrukturen, die im Endeffekt aber alle bei ein und demselben Produkt landen. Da gerade Online-Shops viele Unter- und Kategorieseiten besitzen, sind sie besonders häufig von internem DC betroffen. Als Beispiel ist diesbezüglich folgende Linkstruktur zu nennen:
https://www.beispielshop.de/kategorie1/produktseite/produkt1
https://www.beispielshop.de/produkt1
Die zweite Linkstruktur entsteht, wenn die Detailansicht des Produkts auch ohne zugeordnete Kategorie unmittelbar aufrufbar ist. Werden nun beide Seiten indexiert, liegt für Suchmaschinen Duplicate Content vor.
Das gleiche Problem betrifft URLs mit zusätzlichen Parametern wie eingegebenen Suchbegriffen oder bestimmten Kampagnen-IDs. Führen all diese Beispiel-URLs zur gleichen Seite (und damit zum gleichen Inhalt), wertet Google dies als Duplicate Content:
https://www.example.de/seite1
https://www.example.de/seite1?source=organic
https://www.example.de/seite1?campaignid=3532
Externer Duplicate Content
Bei externem Duplicate Content werden dieselben Inhalte auf verschiedenen Domains dargestellt. Externer DC kann entweder durch Eigen- oder Fremdverschulden zustande kommen. Ersteres ist zum Beispiel dann der Fall, wenn ein Unternehmen mehrere Online-Projekte auf verschiedenen Domains betreibt oder eine Pressemitteilung sowohl auf der eigenen als auch auf anderen Seiten veröffentlichen möchte.
Fremdverschuldeter DC kann wiederum durch Content-Diebstahl entstehen. In diesem Fall taucht Ihr Unique Content plötzlich auf einer fremden Domain auf, wodurch der Google-Algorithmus unter Umständen das Original nicht mehr erkennt, da sowohl ihre eigene Seite als auch die fremde Seite mit den kopierten Inhalten indexiert werden.
Weitere Ursachen für Duplicate Content
- Druckerfreundliche Seiten: Oftmals gibt es die Möglichkeit, eine Druckversion von einer Webseite zu erstellen. Das kann jedoch zu Problemen mit Duplicate Content führen. Die folgenden URLs können nämlich zum Beispiel zur selben Seite führen: https://www.example.com/seite1 und https://www.example.com/drucker/seite1
- PDF-Unterseiten: Gerade bei erklärungsbedürftigen Produkten verwenden viele Webseiten-Betreiber zusätzliche PDFs, die Produktbeschreibungen und Produktinfos beinhalten. Solche sollten aber bereits auf der Produkt-Landingpage angegeben sein.
- Variationsseiten: eine Vielzahl an Detailseiten eines Produkts, die sich nur in Größe oder Farbe unterscheiden.
- Vom Content-Management-System generierte Seiten: Auch ein CMS kann der Grund für Duplicate Content sein, beispielsweise durch Link-Endungen wie /index.htm/ oder /de/.
- Session-IDs: Viele Webseiten möchten die Sessions ihrer Besucherinnen und Besucher verfolgen. Durch Cookies und URI-Attribute (engl. URI = Uniform Resource Identifiers) kann ein Online-Shop beispielsweise feststellen, welche Artikel im Warenkorb der Kundinnen und Kunden gelandet sind. URI-Attribute werden an die URL angehängt und kreieren mehrere Versionen der Seite: https://www.beispielshop.de/seite1 und https://www.beispielshop.de/seite1?sessionid=12455
- Kooperationen: Wenn Sie mit einem anderen Unternehmen eine Content-Kooperation eingehen, kann es schnell passieren, dass beide Parteien rechtmäßig die Inhalte auf ihren Seiten publizieren. Dadurch entsteht ebenfalls externer Duplicate Content.
- Verschiedene URLs, gleiches Ziel: Eine Seite ist über mehrere URLs erreichbar, wie zum Beispiel http://example.com/, http://www.example.com/, https://example.com/ oder https://www.example.com/
Darum ist Duplicate Content problematisch
Diese Probleme können doppelt indexierte Seiten auslösen:
- Suchmaschinen wissen nicht, welche Version der Seite indexiert werden soll.
- Suchmaschinen wissen nicht, welche Version der Seite relevant für die Suchergebnisse ist.
- Die Verleihung der Link Authority durch Suchmaschinen wird erheblich erschwert, wenn zwei verschiedene URLs zum selben Inhalt führen.
- Duplizierte Inhalte lassen sich nicht mit dem Content-Marketing-Grundsatz der „Uniqueness“ vereinbaren, da sie nicht einzigartig sind und den Nutzenden keinen Mehrwert bieten.
Duplicate Content kann dazu führen, dass Ihre Seite die Position im Ranking und, damit verbunden, auch organischen Traffic verliert. Im schlimmsten Fall wertet Google Duplicate Content als Betrugsversuch, wie das Unternehmen auf seinen Support-Seiten klarstellt:
„Gelegentlich werden Inhalte jedoch bewusst in verschiedenen Domains dupliziert, mit der Absicht, das Ranking bei Suchmaschinen zu beeinflussen oder mehr Zugriffe zu generieren. Solche betrügerischen Methoden können die Benutzerfreundlichkeit beeinträchtigen, z. B. weil Besuchern in den Suchergebnissen mehrere Male die gleichen Inhalte angezeigt werden.“
So finden Sie Duplicate-Content
Es gibt einige Tricks und Tools, die Ihnen dabei helfen, Duplicate Content ausfindig zu machen.
Google Search Console
Die Google Search Console kann schnell und einfach Seiten finden, die Google als Duplikate einstuft. Klicken Sie dazu auf „Abdeckung“ unter der Spalte „Index“. Hier sehen Sie, welche Seiten Google indexieren kann und welche nicht – und warum. Auf dem angezeigten Diagramm klicken Sie nun auf „Ausgeschlossen“. Hier finden Sie Seiten, die absichtlich nicht indexiert wurden – von Ihnen oder von Google selbst.

 Hier können Sie nun einsehen, wie Google die unterschiedlichen URLs einstuft:
Hier können Sie nun einsehen, wie Google die unterschiedlichen URLs einstuft:
 Mit einem Klick auf die URL öffnet sich das URL-Prüfungstool, mit dem Sie der Sache auf den Grund gehen können.
Mit einem Klick auf die URL öffnet sich das URL-Prüfungstool, mit dem Sie der Sache auf den Grund gehen können.

Screaming Frog
Das Crawling-Tool Screaming Frog kann einfach heruntergeladen werden und bis zu 500 Seiten kostenlos überprüfen. Diese App verfügt über viele verschiedene Funktionen, sowie auch die Suche nach Duplicate Content.
Seiten Titel/Meta Descriptions
Sie können doppelte Seitentitel und Meta Descriptions ganz einfach unter dem Tab „Page Titles“ oder „Meta Description“ finden. Filtern Sie dann für „Duplicate“ und los geht’s.

URLs
Auch Seiten mit der gleichen URL können beim klicken auf den „URL“ Tab und der Sortierung nach „Duplicate“ gefunden werden.
 Für eine komplette Beschreibung der Funktionen von Screaming Frog können Sie sich den Artikel von SeerInteractive durchlesen. Dieser verrät noch mehr hilfreiche Funktionen und Tipps zur SEO-Analyse.
Für eine komplette Beschreibung der Funktionen von Screaming Frog können Sie sich den Artikel von SeerInteractive durchlesen. Dieser verrät noch mehr hilfreiche Funktionen und Tipps zur SEO-Analyse.
Manuelle Suche
Es gibt zahlreiche Tools, die dabei helfen, Duplicate Content zu finden und zu vermeiden. Weiterhin besteht aber auch die Möglichkeit der manuellen Suche. Dazu können Sie prägnante Textbausteine googeln und anhand der Ergebnisse erkennen, ob der jeweilige Inhalt bereits auf einer Webseite vorhanden ist.
Google geht an dieser Stelle jedoch präventiv vor und zeigt bei der klassischen Suche keine doppelten Inhalte an. Um diese dennoch zu sehen, müssen Sie folgenden Hinweis beachten:

Wenn Sie auf „Suche unter Einbeziehung der übersprungenen Ergebnisse wiederholen" klicken, werden Ihnen die ungefilterten Ergebnisse angezeigt. Dadurch können Sie den manuellen Duplicate-Content-Check durchführen.
Siteliner
Das Online-Tool Siteliner eignet sich, um sich innerhalb kurzer Zeit einen Überblick über möglichen internen Duplicate Content zu verschaffen. Dabei wird die gesamte Webseite nach Duplicate Content durchforstet und in anschaulichen Grafiken angezeigt:

Copyscape
Bei Copyscape können Sie externen Duplicate Content ausfindig machen. Die Bedienung könnte kaum einfacher sein: Sie fügen die gewünschte URL ein und das Tool beginnt seinen Check. Innerhalb von ein paar Sekunden haben Sie dann eine Auflistung von möglichem DC. Beim Klick auf ein Suchergebnis gelangen Sie auf die Detailansicht, wo der gefundene Duplicate Content rot markiert ist:

So beseitigen und vermeiden Sie Duplicate-Content
Duplicate Content ist ein Problem, das sowohl den organischen Traffic als auch Ihr Ranking beeinflussen kann. Wir zeigen Ihnen einige Möglichkeiten auf, wie Sie dieses Problem beseitigen und zukünftig vermeiden können:
1. Canonical Tag
Wenn Sie den Canonical Tag in Ihrem Code nutzen, dann können Sie Suchmaschinen konkret mitteilen, welche Seite für Sie die höchste Relevanz hat. Der Tag wird dabei im Header einer Webseite platziert.
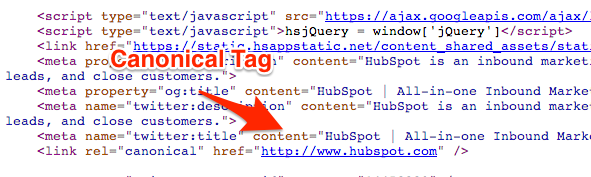
Durch die Verwendung eines solchen Canonicals können Sie mehrere Versionen einer Seite haben und trotzdem Ihre SEO absichern. Wenn Sie HubSpots COS verwenden, dann wird dieser Code automatisch integriert und Sie brauchen sich um manuelles Coden keine Gedanken zu machen.
2. 301-Redirect
Eine 301-Weiterleitung führt alle verwandten Seiten zu einer neuen URL. So weisen Sie Google an, dass die Link Authority zur neuen URL übertragen und diese URL zum Ranking in den Suchergebnissen verwendet werden soll. Besonders empfehlenswert ist ein solcher 301-Redirect bei „www“- und „Nicht-www“-URLs mit dem gleichen Inhalt. So kann die eine auf die andere Seite weiterleiten und nur eine Variante indexiert werden.
Wenn Sie hingegen auf mehrere Versionen Ihrer Seite oder auf bestimmte URL-Parameter angewiesen sind (zum Beispiel Session-IDs), sollten Sie Redirects nicht verwenden.
3. Robot Meta Tags
Ähnlich zu den Canonicals, bei denen die Relevanz einer Seite hervorgehoben wird, können Sie sogenannte Robots Meta Tags verwenden, um einer Suchmaschine mitzuteilen, dass eine bestimmte Seite nicht indexiert werden soll. Der Robots Meta Tag wird im <head>-Abschnitt der jeweiligen Seite platziert und sieht wie folgt aus:
<html>
<head>
<title>…</title>
<meta name=”robots” content=”noindex”/>
</head>
Wichtig zu wissen ist, dass die Anweisung <meta name=”robots” content=”noindex”/> für Suchmaschinen-Crawler gilt. Wenn Sie spezielle Crawler wie den AdsBot-Google blockieren wollen, müssen Sie diese möglicherweise gesondert erwähnen, zum Beispiel <meta name=”AdsBot-Google” content=”noindex”/>.
Der Robots Meta Tag ist dann sinnvoll, wenn Sie die Seite veröffentlichen, aber nicht bei Google indexieren möchten. Sie wird dann nicht in den Suchergebnissen angezeigt und ist nur auf Ihrer Webseite einsehbar.
4. Link-Attribut „hreflang“
Bei Webseiten, die mehrsprachig und für verschiedene Länder ausgerichtet sind, tritt Duplicate Content besonders häufig auf – denn der Inhalt selbst ist in der Regel derselbe, wird aber auf unterschiedlichen Länderdomains (zum Beispiel .de, .com oder .fr) indexiert. Um dies zu vermeiden, kann man Google über das hreflang-Attribut mitteilen, wie es die URLs geografisch ausrichten muss.
Die hreflang-Anmerkung wird in der Kopfzeile <head> des HTML-Codes platziert und sieht zum Beispiel folgendermaßen aus:
<link rel = ”alternate” href = ”https://beispielseite.de/”hreflang = ”de”>
<link rel = ”alternate” href = ”https://beispielseite.de/at/”hreflang = ”de-at”>
Beim zweiten Beispiel erkennen Sie, dass das hreflang-Attribut eigentlich aus zwei Komponenten besteht: einmal der Sprachcode („de“) und einmal der Ländercode („at“). Im ersten Beispiel ist beides identisch und muss deshalb nicht doppelt angegeben werden. Dieses ISO-Format für Sprachen und Länder ist absolut zwingend und Voraussetzung, damit der Googlebot die vorliegende Information richtig verarbeiten kann.
Beachten Sie zwei Dinge, wenn Sie den hreflang-Tag benutzen:
- Er ersetzt nicht den Canonical Tag.
- Er verbessert nicht die SEO-Performance, wenn Sie nur eine Version der Webseite haben.
Fazit: So finden und beseitigen Sie Duplicate Content
Als Duplicate Content bezeichnet man identische Inhalte, die von verschiedenen URLs aus zu erreichen sind. Dies kann sowohl intern auf der eigenen Webseite als auch extern durch Kooperationen oder Content-Klau auftreten. Das Problem daran ist, dass Suchmaschinen nicht mehr erkennen, welcher Inhalt das Original ist und oberste Relevanz hat.
Auch wenn Duplicate Content nicht zwangsweise zu einer Abstrafung durch Google führt, kann dieser Ihrer Webseite enorm schaden und beispielsweise Probleme mit der Indexierung verursachen oder Ihr Ranking in den Suchergebnissen negativ beeinflussen.
Um Duplicate Content ausfindig zu machen, stehen Ihnen neben der Google Search Console auch verschiedene Tools wie Copyscape oder Screaming Frog zur Verfügung. Haben Sie es mit externem DC zu tun, der nicht selbstverschuldet ist, sollten Sie den Betreiber der anderen Webseite darauf hinweisen. Bei internem DC helfen wiederum verschiedene HTML-Tags oder 301-Redirects, um den Suchmaschinen mitzuteilen, welche URLs zum Beispiel die höchste Relevanz haben oder indexiert werden sollen.
Verfallen Sie bei diesem Thema aber nicht in Panik. 100 Prozent unique Webseiten sind zwar theoretisch anzustreben, in der Realität aber oft schwer zu erreichen (vor allem was externen DC betrifft). Vermeiden Sie interne und externe Fehler, die unnötigen Duplicate Content erzeugen, und achten Sie konsequent darauf einzigartige Inhalte zu erstellen. Auf diese Weise geben Sie Google keinerlei Anlass, die Relevanz Ihrer eigenen Inhalte zu hinterfragen.

Titelbild: HAKINMHAN / iStock / Getty Images Plus
Onpage Seo









