Spätestens seit 2013 entwickelt sich Google nach und nach zu einer hundertprozentigen semantischen Suchmaschine. Es gibt viele Erklärungen, was eine semantische Suche ist und was sie ausmacht. Aber genau so viele Erklärungen sind sehr ungenau und es gibt viele Missverständnisse. Dieser Beitrag wird als Deep Dive versuchen, die semantische Suche fundiert zu erklären.

![]()
Googles Weg zu einer semantischen Suchmaschine
Googles Bemühungen für die Entwicklung einer semantischen Suchmaschine sind bis zum Jahr 1999 zurückzuverfolgen (siehe dazu diesen Beitrag vom vermissten Bill Slawski). Wirklich konkret und in der Praxis erlebbar wurde die semantische Suche mit der Einführung des Knowledge Graphs im Jahr 2012 und die grundlegende Veränderung des Ranking-Algorithmus-Update Hummingbird 2013.
Alle weiteren großen Innovationen wie Rankbrain, E-A-T, BERT oder MUM hatten direkt oder indirekt mit der Weiterentwicklung zu einer semantischen Suchmaschine zu tun.
Durch die Einführung von Natural Language Processing in die Suche entwickelt sich Google exponentiell schnell in Richtung einer hundertprozentig semantischen Suchmaschine.
Was ist semantische Suche?
Eine semantische Suchmaschine berücksichtigt den semantischen Kontext von Suchanfragen und Inhalten, um die Bedeutung besser zu verstehen. Im Gegensatz zu rein Keyword basierten Such-Systemen soll in der semantischen Suche die Bedeutung der Suchanfrage und von Dokumenten besser interpretiert werden.

Quelle: Eigene Darstellung Olaf Kopp
Während Keyword-basierte Suchmaschinen auf Grundlage eines Keyword-Text-Abgleichs funktionieren, berücksichtigen semantische Suchmaschinen auch die Beziehungen zwischen den Entitäten für die Ausgabe von Suchergebnissen.
Viele Definitionen, die man zur semantischen Suche findet, fokussieren sich auf die Interpretation der Suchintention als Wesen der semantischen Suche. Aber in erster Linie geht es bei der semantischen Suche um das Erkennen der Bedeutung von Suchanfragen und Inhalten anhand der vorkommenden Entitäten.
Semantik = Bedeutungslehre.
Bedeutung ist aber nicht gleich Intention.
Die Suchintention beschreibt die Erwartung, die ein Nutzer an die Suchergebnisse stellt. Die Bedeutung ist etwas anderes.
Die Identifikation der Bedeutung kann dabei helfen, die Suchintention zu erkennen, ist aber eher ein Zusatznutzen der semantischen Suche.
Hummingbird: Not strings, but things!
Hummingbird kann als Startschuss für die Entwicklung hin zu einer semantischen Suchmaschine verstanden werden. Es war die größte Veränderung beim Search Query Processing und Ranking, die Google jemals durchgeführt hat und betraf bereits 2013 über 90% aller Suchanfragen. Man kann sagen, dass Hummingbird ein grundlegender Austausch eines Großteils der bestehenden Ranking-Algorithmen war.
Durch die Einführung von Hummingbird war Google ab sofort in der Lage, beim Query Processing, dem Ranking und der Ausgabe der SERPs im Knowledge Graph erfasste Entitäten mit einzubeziehen.
Eine Entität beschreibt das Wesen bzw. die Identität eines konkreten oder abstrakten Gegenstand des Seins. Entitäten sind eindeutig identifizierbar und damit einzigartig von Bedeutung.
Grundsätzlich kann zwischen „Named Entities“ (Benannte Entitäten) und abstrakten Konzepten unterschieden werden. Benannte Entitäten sind Objekte aus der echten Welt, wie z.B. Personen, Orte, Organisationen, Produkte, Events usw. Abstrakte Konzepte sind physikalischer, psychologischer oder sozialer Natur, wie z.B. Entfernung, Quantität, Emotionen, Menschenrechte, Friede usw.
Vor Hummingbird hat Google in erster Linie ein Keyword-Dokument-Matching für das Ranking für das Ranking durchgeführt. Die Bedeutung einer Suchanfrage oder von Inhalten konnte Google nicht erkennen.
Die Rolle vom Knowledge Graph in der semantische Suche bei Google
Für ein Entitäten-basiertes Ranking bedarf es auch ein Entitäten-basiertes Indexing. Der Knowledge Graph ist Googles Entitäten-Index, in dem Beziehungen zwischen den Entitäten berücksichtigt werden. Klassische Indizes sind in tabellarischer Form organisiert und lassen dadurch keine Abbildung der Beziehungen zwischen Datensätzen zu.
Ein Knowledge Graph ist eine semantische Datenbank, in der Informationen so strukturiert aufgearbeitet sind, dass aus den Informationen Wissen entsteht. In einem Knowledge Graph werden Entitäten (Knoten) über Kanten in Beziehung zueinander gestellt, mit Attributen und weiteren Informationen versehen und in thematischen Kontext bzw. Ontologien gebracht.
Entitäten sind das zentrale Organisations-Element in semantischen Datenbanken wie dem Knowledge Graph von Google.
Neben den Beziehungen zwischen den Entitäten sammelt Google über Data Mining Attribute und weitere Informationen zu den Entitäten und organisiert diese rund um die Entitäten.
Wenn man nach einer Entität googlet, bekommt man einen Eindruck davon, welche Quellen und Informationen Google für eine Entität berücksichtigt.

Quelle: Screenshot Google-Suche
Die favorisierten Quellen, Attribute und Informationen variieren je nach Entitäten-Typ. Bei einer Personen-Entitäten sind diese anders als bei einer Event-Entität oder Organisations-Entität. Das ist auch entscheidend dafür, welche Informationen in einem Knowledge Panel angezeigt werden.
Mehr zu den zentralen Organisations-Elementen rund um eine Entitäten-basierte Indexierung finden Sie im Beitrag „Alles was Du zu Entitäts-Typen, -Klassen & Attributen wissen solltest“.
Die Struktur eines Entitäten-basierten Index erlaubt es, Antworten auf Fragen zu geben, in denen ein Thema oder eine Entität gesucht wird, die in der Frage nicht genannt wird.

Quelle: Screenshot Google-Suche
In diesem Beispiel sind „Australien“ und „Canberra“ die Entitäten und der Wert „Hauptstadt“ beschreibt die Art der Beziehung. Eine Keyword-basierte Suchmaschine hätte diese Antwort nicht ausgeben können.
Als Grundlage für einen Knowledge Graph dienen drei Ebenen:
- Entitäten-Katalog: Hier werden alle Entitäten gespeichert, die mit der Zeit identifiziert worden sind.
- Knowledge Repository: Die Entitäten werden in einem Wissensdepot (Knowledge Repository) mit den Informationen bzw. Attributen aus verschiedenen Quellen zusammengeführt.
Im Knowledge Repository geht es in erster Linie um die Zusammenführung und Speicherung von Beschreibungen und die Bildung semantischer Klassen bzw. Gruppen in Form von Entitätstypen.
Die Daten generiert Google über den Knowledge Vault. Über den Knowledge Vault ist es Google möglich, Data Mining aus unstrukturierten Quellen zu betreiben.
- Knowledge Graph: Im Knowledge Graph werden die Entitäten mit Attributen verknüpft und Beziehungen zwischen Entitäten hergestellt.
Für die Identifikation von Entitäten und den dazugehörigen Informationen kann Google auf verschiedene Quellen zurückgreifen.

Nicht alle im Knowledge Repository erfassten Entitäten werden in den Knowledge Graph übernommen. Folgende Kriterien könnten über die Aufnahme in den Knowledge Graph entscheiden:
- Nachhaltige gesellschaftliche Relevanz
- Genügend Suchtreffer für die Entität im Google-Index
- Anhaltende öffentliche Wahrnehmung
- Einträge in einem anerkannten Lexikon oder einer anerkannten Enzyklopädie bzw. in einem fachspezifischen Nachschlagewerk
Es ist davon auszugehen, dass Google in einem Knowledge Repository wie z.B. dem Knowledge Vault deutlich mehr Long-Tail-Entitäten erfasst hat als im Knowledge Graph und diese für die semantische Suche nutzt.
Über das Crawling des offenen Internets und Natural Language Processing ist Google in der Lage unabhängig von strukturierten und semistrukturierten Datenbanken Entity- und Data-Mining skalierbar durchzuführen und den Knowledge Vault mit immer mehr Informationen auch zu Longtail-Entitäten zu versorgen.

Quelle: Eigene Darstellung Olaf Kopp
Wie funktioniert Google als semantische Suchmaschine?
Google nutzt die semantische Suche in den folgenden Bereichen:
- Verständnis von Suchanfragen bzw. Entitäten beim Search Query Processing
- Verstehen der Inhalte über Entitäten für das Ranking
- Verstehen der Inhalte und Entitäten für das Data Mining
- Kontextuelle Einordnung von Entitäten für eine spätere E-A-T-Bewertung
Die Google-Suche basiert heute auf einem Search-Query-Processor für die Interpretation von Suchanfragen und der Zusammenstellung von Korpussen aus für die Suchanfrage relevanten Dokumenten. Hier kommen wahrscheinlich BERT, MUM und Rankbrain zum Einsatz.
Im Search Query Processing werden die Suchterme mit den in den semantischen Datenbanken erfassten Entitäten abgeglichen, ggf. verfeinert oder umgeschrieben.
Im nächsten Schritt wird die Suchintention bestimmt und ein passender Korpus aus x Inhalten ermittelt.
Dabei greift Google sowohl auf den klassischen Such-Index, als auch auf die eigene semantische Datenbank in Form des Knowledge Graph zurück. Es ist wahrscheinlich, dass zwischen diesen beiden Datenbanken ein Austausch über eine Schnittstelle stattfindet.
Eine Scoring Engine aus verschiedenen Algorithmen basierend auf dem Kern-Algorithmus von Hummingbird ist für das Scoring, also die Bewertung der Inhalte, zuständig und bringt diese dann anhand des Scorings in eine Reihenfolge. Bei dem Scoring geht es um die Relevanz eines Inhalts in Bezug auf die Suchanfrage bzw. Suchintention.
Da Google neben der Relevanz auch die Qualität von Inhalten bewerten möchte, muss noch eine Bewertung nach E-A-T-Kriterien erfolgen.
Für diese E-A-T-Bewertung muss Google die Expertise, Autorität und Trustworthiness der Domain, des Publishers und/oder Autors bzw. der Autorin bewerten. Hierfür können die semantischen Entitäten-Datenbanken die Grundlage sein.
Über eine Cleaning Engine werden diese Suchergebnisse dann von Duplikaten befreit und etwaige Abstrafungen berücksichtigt.
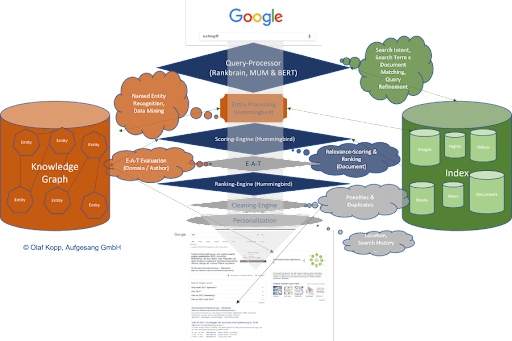
Quelle: Eigene Darstellung Olaf Kopp
Was bedeutet das jetzt für semantische SEO?
Ich lese sehr viel über strukturierte Daten, die semantische Optimierung von Inhalten oder Aufbau von semantischen Themenwelten, wenn es um semantische SEO geht.
Ja, es ist sinnvoll Google zu zeigen, dass man bestimmte Themen mit seinen Inhalten vollständig abdeckt und damit Expertise zeigt.
Es gibt einige Patente, bei denen es um den Abgleich von Dokumenten im internen Knowledge Graphen mit dem Google Knowledge Graph geht. Die Theorie besagt , dass eine hohe Übereinstimmung der in einem Text verwendeten Entitäten mit den Beziehungsstrukturen der Haupt-Entität in Googles semantischer Datenbank zu besseren Rankings führt.
Das klingt logisch. Aber sind wir mal ehrlich, im Endeffekt unterscheidet sich hier die Keyword-basierte Optimierung nicht wesentlich von einer Entitäten-basierten Optimierung von Inhalten.
Auch der Aufbau von Themenwelten ist sinnvoll, wobei man sagen muss, dass in Zeiten von Passage Ranking überlegt werden sollte, wie stark man ein Thema in verschiedene Unterthemen zerpflückt bzw. für jedes Unterthema einen eigenen Inhalt produziert oder doch nur einen holistisches Content Asset erstellt.
Und strukturierte Daten können Google helfen, semantische Zusammenhänge zu verstehen, aber nur so lange, bis sie nicht mehr benötigt werden. Und das wird bald sein.
Meiner Meinung nach ist Google so gut im maschinellen Lernen, dass sie strukturierte Daten verwenden, um die Algorithmen immer schneller zu trainieren. Es ist zum Beispiel dasselbe wie Markups für Social-Media-Profile. Es dauerte genau ein Jahr von der Empfehlung von Google, die Markups zu verwenden, bis zur Ankündigung, dass sie es jetzt ohne strukturierte Daten sehen können.
Strukturierte Daten sind zudem keine gute Grundlage für eine Bewertung. Man hat sie oder man hat sie nicht.
Das alles kann man gerne zu semantischer SEO zählen. Was mir allerdings häufig fehlt, ist die globale Betrachtungsweise von Entitäten als Publisher und Autoren. Hier spielen mehr Offpage- als Onpage-Signale eine Rolle. Google will aufgrund der Beziehungen zwischen autoritären und glaubwürdigen Entitäten feststellen, welche Domains und Autorinnen gemäß E-A-T die qualitativ besten Quellen für ein Themenfeld sind.
Wer steht mit wem in Beziehung? Wer empfiehlt wen? Wer hängt mit wem ab?
Als Faktoren für diese Nähe zwischen Autoritäts-Entitäten können sowohl Verlinkungen als auch Kookkurrenzen von Google herangezogen werden (Kookurrenz steht für das gemeinsame Auftreten zweier oder mehrerer Wörter in einer übergeordneten Einheit.). Und unter semantischer SEO verstehe ich auch, diese zu fördern.
Und wenn wir beim Thema Kookkurrenzen sind, sollte man bei der Optimierung von Inhalten auch die Funktionsweisen von Natural Language Processing berücksichtigen. Google nutzt Natural Language Processing, um Entitäten und deren Kontext zu identifizieren. Das funktioniert über grammatische Satzstrukturen, Triples und Tuples aus Nomen und Verben.
Deswegen sollten wir bei der semantischen SEO auch auf eine grammatikalisch einfache Satzstruktur achten. Lieber kurze Sätze ohne Personalpronomen und Verschachtelungen. So bedienen wir Nutzerinnen und Nutzer hinsichtlich Lesbarkeit und Suchmaschinen.
Fazit: Die Zukunft der semantischen Suche oder wann wir eine zu 100 % auf Entitäten basierende Google-Suche haben?
Ich denke, dass es in Zukunft einen verstärkten Austausch zwischen dem klassischen Google-Suchindex und dem Knowledge Graph über eine Schnittstelle geben wird.
Je mehr Entitäten im Knowledge Graph erfasst werden, desto größer ist der Einfluss auf die SERPs. Allerdings steht Google nach wie vor vor der großen Herausforderung, Vollständigkeit und Genauigkeit in Einklang zu bringen.
Für das eigentliche Scoring durch Hummingbird spielen die Entitäten auf Dokumentenebene keine große Rolle. Sie sind vielmehr ein wichtiges Organisationselement zum Aufbau ungewichteter Dokumentenkorpusse auf der Suchindexseite.
Das eigentliche Scoring der Dokumente erfolgt durch Hummingbird nach klassischen Information-Retrieval-Regeln. Auf Domain-Ebene sehe ich jedoch den Einfluss von Entitäten auf das Ranking viel höher. Stichwort: E-A-T.
Ich denke, dass die nächsten Jahre eine große Rolle für den zunehmenden Einfluss von Entitäten in der Google-Suche spielen werden. Das neue Erscheinungsbild der entitätsbasierten Suche zeigt sehr deutlich, wie Google die Indexierung von Informationen und Inhalten rund um die Entität nach und nach organisiert. Dies zeigt auch, wie stark Innovationen wie MUM der Idee einer semantischen Suche folgen.

Titelbild: Prasert Prapanoppasin / iStock / Getty Images Plus
Hinweis: Bei diesem Beitrag handelt es sich um einen Gastbeitrag von Olaf Kopp, Experte für Online-Marketing und Head of SEO bei der Online Marketing Agentur Aufgesang GmbH.
Seo



.png)


%20(27).png)